
%pip install -q sentence-transformersThe Library
and
the Maze
CZ PyCon 2023
Karel Minařík
This Talk is a Jupyter Notebook
“The self-attention mechanism uses multiple heads to capture different aspects of the sequence. Each head uses scaled dot-product attention to weight the importance of various parts of the input sequence when producing each element of the output sequence.”
“The vanishing gradient problem in RNNs is often mitigated by adopting architectures like LSTM (Long Short-Term Memory) or GRU (Gated Recurrent Units), which introduce gating mechanisms to control the flow of information.”
“The masked language model (MLM) pre-training objective allows BERT to learn bidirectional representations by randomly masking tokens and predicting them based on their context, using the Transformer’s encoder architecture. Fine-tuning is then performed using a task-specific head layer over the pre-trained embeddings.”
“The model is trained using stochastic gradient descent (SGD) with a learning rate decay, optimized on the cross-entropy loss. The final output layer uses a softmax activation function to produce class probabilities, which are converted to logits for evaluation.”
“LoRA augments pre-trained Transformer models by adding learnable, layer-wise recurrent mechanisms. This enables the model to adapt to new tasks without requiring extensive fine-tuning and mitigates the catastrophic forgetting problem.”
“The embeddings are initialized randomly and updated via backpropagation. These high-dimensional vectors capture syntactic and semantic information and are fed into a stack of convolutional and fully connected layers for downstream tasks.”
(Content generated by AI)
\[ \theta_{j} := \theta_{j} - \alpha \frac{1}{m} \sum_{i=1}^{m} (h_{\theta}(x^{(i)}) - y^{(i)}) x_j^{(i)} \]
ChatGPT by OpenAI
Announced in November 2022
A “cambrian explosion” of interest in artificial intelligence
Many problems in IT will be
reframed as AI problems
Trivial example: extracting data from text
Our Itinerary
- What are text embeddings?
- Use case: Semantic Search
- Embeddings for other media
➊ What Are Text Embeddings?
What Are Text Embeddings?
Basic mechanism for natural language processing
(LLMs, machine translation, sentiment analysis, …)Numerical representations of text
(Words, phrases, sentences …)“Long lists of numbers”
“GPS coordinates” for meaning
➊ What Are Text Embeddings?
Let’s initialize a small model.
![]()
sentence-transformers/all-MiniLM-L6-v2
➊ What Are Text Embeddings?
Let’s create embeddings for two words.
➊ What Are Text Embeddings?
[0.03733039, 0.0511619, -0.00030606816, 0.060209926, -0.11749442, '...'][-0.05314704, 0.014194381, 0.0071458234, 0.06860866, -0.07848035, '...']What Are the “Dimensions”?
print(len(embeddings_for_dog))
# => 384
print(model1.get_sentence_embedding_dimension())
# => 384The model captures 384 different aspects of the word’s meaning, usage, or context.
For example:
- the emotional tone (positive, negative, neutral?)
- the usage patterns (common or rare? in which genre?)
- the social setting (formal or informal?)
➊ What Are Text Embeddings?
Let’s put the embeddings into a pandas dataframe,
so we can make transformations and manipulations.
➊ What Are Text Embeddings?
Let’s transform the data for a visualization.
➊ What Are Text Embeddings?
def df_for_heatmap(df):
return (
df.copy(deep=True)
# Store the embeddings index as `position`
.assign(
position=[
list(range(len(x))) for x in df.embeddings
])
# Convert the index into a regular column
.reset_index()
# Convert from "wide" to "long" format
.explode(["embeddings", "position"])
# Rename columns for more clarity
.rename(
columns={"index": "animal",
"embeddings": "embedding"})
)
source = df_for_heatmap(df1)
source| animal | embedding | position | |
|---|---|---|---|
| 0 | cat | 0.03733 | 0 |
| 0 | cat | 0.051162 | 1 |
| 0 | cat | -0.000306 | 2 |
| 0 | cat | 0.06021 | 3 |
| 0 | cat | -0.117494 | 4 |
| ... | ... | ... | ... |
| 1 | dog | 0.03667 | 379 |
| 1 | dog | 0.111445 | 380 |
| 1 | dog | 0.029857 | 381 |
| 1 | dog | 0.023905 | 382 |
| 1 | dog | 0.110093 | 383 |
768 rows × 3 columns
Let’s make a simple heatmap visualization.
➊ What Are Text Embeddings?
import altair as alt
def heatmap(df):
return alt.Chart(
df
).encode(
alt.X("position:N", title="").axis(labels=False, ticks=False),
alt.Y("animal:N", title="", sort=df["animal"].unique()).axis(labelLimit=300, tickWidth=0, labelFontWeight="bold"),
alt.Color("embedding:Q").scale(scheme="goldred").legend(None),
).mark_rect(
width=3
).properties(
width=alt.Step(3), height=alt.Step(50)
).configure_axis(
grid=False,
domain=False
)
heatmap(source)Let’s reduce the dimensionality.
➊ What Are Text Embeddings?
import numpy as np
from sklearn.decomposition import PCA
# Convert embeddings into a 2-dimensional array
def df_to_reduced(df):
reducer = PCA(n_components=2)
return df.copy().assign(
embeddings=reducer.fit_transform(np.stack(df["embeddings"])).tolist()
)
df_to_reduced(df1)| embeddings | |
|---|---|
| cat | [-0.41192373633384705, 3.2534185123722636e-08] |
| dog | [0.4119238257408142, 3.253417801829528e-08] |
Let’s make a function for a scatterplot.
➊ What Are Text Embeddings?
import numpy as np
import pandas as pd
import altair as alt
def scatterplot(data: pd.DataFrame, tooltips=False, labels=False, jitter=0.0, width=800, height=200):
data["xJittered"] = data['x'] + np.random.normal(0, jitter, size=len(data))
data["yJittered"] = data['y'] + np.random.normal(0, jitter, size=len(data))
base_chart = (
alt.Chart(data).encode(
alt.X("xJittered", scale=alt.Scale(zero=False), title=None),
alt.Y("yJittered", scale=alt.Scale(zero=False), title=None),
).properties(width=width, height=height))
if tooltips:
base_chart = base_chart.encode(alt.Tooltip(["text"]))
circles = base_chart.mark_circle(size=200, color="crimson", stroke="white", strokeWidth=1)
if labels:
labels = base_chart.mark_text(fontSize=13,align="left",baseline="bottom",dx=5).encode(text="text")
chart = circles + labels
else:
chart = circles
return chartLet’s display the scatterplot.
➊ What Are Text Embeddings?
Let’s add some more words.
➊ What Are Text Embeddings?
words = ["cat", "dog", "pizza", "coffee", "asymptomatic"]
df2 = pd.DataFrame(
[ [model1.encode(word)] for word in words ],
index=words, columns=["embeddings"])
df2| embeddings | |
|---|---|
| cat | [0.03733039, 0.0511619, -0.00030606816, 0.0602... |
| dog | [-0.05314704, 0.014194381, 0.0071458234, 0.068... |
| pizza | [-0.08696939, 0.06991054, -0.0150973685, 0.096... |
| coffee | [-0.03095191, 0.018730178, 0.014911181, 0.1197... |
| asymptomatic | [0.031974357, 0.020842418, -0.064985596, 0.171... |
Let’s try the scatterplot again.
➊ What Are Text Embeddings?
The Theory of Language
Ferdinand de Saussure, Course in General Linguistics (1916)

Language is a system of signs
Signs represent concepts, not things
The nature of the sign is arbitrary
(…) what is natural to mankind is not oral speech but the faculty of constructing a language, i.e. a system of distinct signs corresponding to distinct ideas.
Let’s try a word in a different language.
➊ What Are Text Embeddings?
Let’s try the scatterplot again.
➊ What Are Text Embeddings?
Let’s try with a different model.
![]()
sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
➊ What Are Text Embeddings?
Let’s create the embeddings with the new model.
➊ What Are Text Embeddings?
words = df3.index.to_list()
df4 = pd.DataFrame(
[ [model2.encode(word)] for word in words ],
index=words, columns=["embeddings"])
df4| embeddings | |
|---|---|
| cat | [0.59055364, -0.3334293, -0.03257506, 0.543022... |
| dog | [0.280045, -0.24335869, -0.25790253, 0.1898756... |
| pizza | [-0.31320187, -0.17622907, -0.17177011, -0.066... |
| coffee | [-0.19748689, -0.38310185, -0.1273405, 0.75054... |
| asymptomatic | [0.05101946, -0.042016577, -0.04529487, 0.4346... |
| kočka | [0.5026489, -0.23199998, -0.008454391, 0.48297... |
… and let’s try the scatterplot again.
➊ What Are Text Embeddings?
Let’s compute similarity between a query and the other words.
➊ What Are Text Embeddings?
from sklearn.metrics.pairwise \
import cosine_similarity
query = "cat"
query_emb = model2.encode(query)
similarities = {}
for word, embeddings in df4["embeddings"].items():
# query vector ⇔ word vector
similarities[word] = cosine_similarity(
[query_emb],
[embeddings]
)[0][0]
# Display the similarities
(
pd.DataFrame({
"Word": [f"{query} ⇔ {k}" for k in similarities.keys()],
"Similarity": similarities.values()
})
.sort_values(by=["Similarity"], ascending=False)
.style
.hide(axis="index")
.set_table_attributes('class="dataframe"')
.bar(subset=['Similarity'], color='#999')
)| Word | Similarity |
|---|---|
| cat ⇔ cat | 1.000000 |
| cat ⇔ kočka | 0.983700 |
| cat ⇔ dog | 0.303288 |
| cat ⇔ pizza | 0.250888 |
| cat ⇔ coffee | 0.209838 |
| cat ⇔ asymptomatic | 0.112521 |
What is “cosine similarity”?
import matplotlib.pyplot as plt
A, B, C = np.array([6,7]), np.array([8,9]), np.array([2,10])
# Stack vectors into a single matrix
vectors = np.vstack([A, B, C])
print(vectors)
# Calculate cosine similarity matrix
cos_sim_matrix = cosine_similarity(vectors)
# Calculate angles in degrees
theta_AB = np.arccos(cos_sim_matrix[0, 1]) * (180 / np.pi)
theta_AC = np.arccos(cos_sim_matrix[0, 2]) * (180 / np.pi)
# Origin coordinates
origin = np.zeros((3, 2))
# Display the "quiver" chart
plt.figure(figsize=(10, 10))
plt.title("Cosine Similarity For Vectors A, B, C")
plt.quiver(origin[:, 0], origin[:, 1], vectors[:, 0], vectors[:, 1],
angles='xy', scale_units='xy', scale=1, color=['r', 'g', 'b'])
plt.xlim(-1, 11)
plt.ylim(-1, 11)
plt.xlabel("X-axis")
plt.ylabel("Y-axis")
plt.grid()
plt.text(A[0], A[1], 'A', color='black', fontsize=24, ha='right')
plt.text(B[0], B[1], 'B', color='black', fontsize=24, ha='right')
plt.text(C[0], C[1], 'C', color='black', fontsize=24, ha='right')
plt.text(A[0] / 2.5, A[1] / 2.5, f'{theta_AB:.2f}°', color='black', fontsize=12, ha='center')
plt.text(A[0] / 2.5, A[1] / 1.5, f'{theta_AC:.2f}°', color='black', fontsize=12, ha='center')
plt.show()[[ 6 7]
[ 8 9]
[ 2 10]]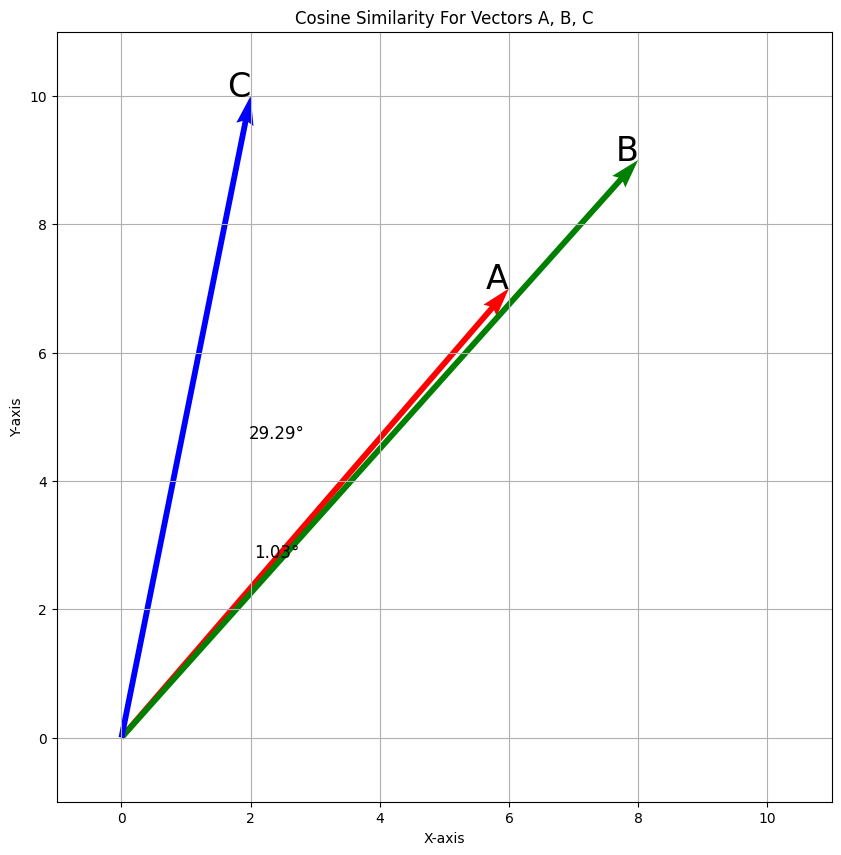
Let’s do “word arithmetics”.
➊ What Are Text Embeddings?
words = ["king", "man", "woman", "queen", "saxophone"]
df6 = pd.DataFrame(
[ [model2.encode(word)] for word in words ],
index=words, columns=["embeddings"])
df6| embeddings | |
|---|---|
| king | [-0.009882803, 0.6362919, -0.105976604, -0.097... |
| man | [-0.0053758374, 0.26451156, -0.1168356, -0.215... |
| woman | [0.17876714, -0.28030494, -0.008455522, 0.4727... |
| queen | [0.36926943, -0.03183403, 0.13288921, 0.218695... |
| saxophone | [0.09851525, 0.36520788, 0.004772159, -0.50931... |
king - man + woman = ?
➊ What Are Text Embeddings?
result = (
df6.loc["king"]["embeddings"]
-
df6.loc["man"]["embeddings"]
+
df6.loc["woman"]["embeddings"])
print("Result:", list(result[:3]) + ["..."])
similarities = {}
for word, embeddings in df6["embeddings"].items():
# result vector ⇔ word vector
similarities[word] = \
cosine_similarity([result], [embeddings])[0][0]
# Display the similarities
(
pd.DataFrame({
"Word": similarities.keys(),
"Similarity": similarities.values()
})
.sort_values(by=["Similarity"], ascending=False)
.style
.hide(axis="index")
.set_table_attributes('class="dataframe"')
.bar(subset=['Similarity'], color='#999')
)Result: [0.17426018, 0.09147543, 0.0024034753, '...']| Word | Similarity |
|---|---|
| queen | 0.790001 |
| king | 0.675087 |
| woman | 0.639414 |
| saxophone | 0.204697 |
| man | 0.141279 |
➋ Semantic search
Semantic search
Lexical search (TF-IDF, BM25, …)
Semantic search: text embeddings and similarity
Meaning (“dimensions”), not terms
(Approximate) “Nearest Neighbors” algorithm
➋ Semantic search
Nearest Neighbors with scikit-learn
➋ Semantic search
from sklearn.neighbors import NearestNeighbors
from sklearn.preprocessing import MinMaxScaler
# Initialize the model
nn = NearestNeighbors(n_neighbors=len(df6["embeddings"]))
# Store the embeddings for efficient lookup
nn.fit(df2["embeddings"].tolist())
# Define the search query
query = "food"
query_embedding = np.array([model1.encode(query)])
# Compare query vector to every vector in the dataset
distances, indices = nn.kneighbors(query_embedding)
# Normalize the distances to [0-1]
scaler = MinMaxScaler()
normalized_distances = scaler.fit_transform(distances.reshape(-1, 1))
# Display the results
(pd.DataFrame({
"word": df2.index[indices.flatten()],
"distance": normalized_distances.flatten(),
})
.style
.hide(axis="index")
.set_table_attributes('class="dataframe align-left"')
.set_caption(f"Query: {query}")
.background_gradient(subset=["distance"], cmap="Greys", ))| word | distance |
|---|---|
| pizza | 0.000000 |
| coffee | 0.279945 |
| dog | 0.355471 |
| cat | 0.465242 |
| asymptomatic | 1.000000 |
Nearest Neighbors with Annoy
- Download data from coffee.stackexchange.com
- Extract post titles from XML into Pandas’ dataframe
- Compute the text embeddings
- Build the Annoy index
- Search the index
➋ Semantic search
Extract Titles from XML into a DataFrame
➋ Semantic search
import pandas as pd
from py7zr import SevenZipFile as zip
xml_file = "Posts.xml"
dest = tempfile.TemporaryDirectory().name
# Extract the file with posts
with zip(input_file_path, "r") as archive:
archive.extract(targets=[xml_file], path=dest)
# Read XML into a dataframe
df = pd.read_xml(os.path.join(dest, xml_file), xpath="//row")
# Keep only 'Title' column and rename to 'text'
df = df[["Title"]].dropna().rename(columns={"Title": "text"})
display(df.head(5).style.hide(axis="index"))
print(f"{df.size} rows")| text |
|---|
| How should I store whole bean coffee? |
| How fine should I grind coffee for drip/pour over coffee |
| Does the hardness of water matter when making coffee? |
| What's the theory behind using thin spouted kettles when making drip/pour over coffee |
| How important is tamping coffee for an espresso machine |
1450 rowsCompute the Text Embeddings
➋ Semantic search
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
# Register progress bar
tqdm.pandas(desc="Process")
# Compute embeddings
df["embeddings"] = df["text"].progress_apply( lambda x: model.encode(x) )
df.head(3)| text | embeddings | |
|---|---|---|
| 0 | How should I store whole bean coffee? | [-0.4377262, 0.14942853, -0.16667569, 0.167280... |
| 1 | How fine should I grind coffee for drip/pour o... | [-0.24292755, -0.36047038, 0.0934966, 0.396481... |
| 2 | Does the hardness of water matter when making ... | [-0.11959872, -0.2570504, 0.18188146, 0.378879... |
Build the Index
➋ Semantic search
from annoy import AnnoyIndex
f = df["embeddings"][0].size # Vector dimensions
t = AnnoyIndex(f, "angular")
for i, vector in enumerate(df["embeddings"]):
t.add_item(i, vector)
t.build(10) # 10 trees
t.save(os.path.join("tmp", "coffee.ann"))
print(f"Built index with [{df.embeddings.size}] items and [{f}] dimensions")Built index with [1450] items and [384] dimensionsLoad the Index and Define the Search Method
➋ Semantic search
# Load the saved index
#
index = AnnoyIndex(f, "angular")
index.load(os.path.join("tmp", "coffee.ann"))
# Define the search method
#
def search(query, index, model, df):
query_embedding = model.encode(query)
nearest_ids = index.get_nns_by_vector(query_embedding, 10)
return df.iloc[nearest_ids][["text"]]Perform the Search
➋ Semantic search
CPU times: user 41.9 ms, sys: 14.6 ms, total: 56.5 ms
Wall time: 42.3 ms| text | |
|---|---|
| 208 | How many cups of coffee is it safe to consume per day? |
| 1686 | What is the limit to the amount of coffee one can consume? |
| 3006 | What should be the daily coffee intake? |
| 2270 | How much "coffee" is there in my cup? |
| 3043 | Is one cup of coffee a day good? |
| 792 | Coffee on daily basis |
| 4424 | How much coffee is too much? |
| 2673 | Coffee consuming amount |
| 4353 | How Much Caffeine is Really in Your Coffee? - analysis / questions |
| 3218 | How do I vary between how much froth for each coffee drink? |
Perform the Search
➋ Semantic search
CPU times: user 41.5 ms, sys: 13.5 ms, total: 55 ms
Wall time: 39.9 ms| text | |
|---|---|
| 1686 | What is the limit to the amount of coffee one can consume? |
| 4404 | What is the minimum amount of coffee that produces the maximum possible concentration? |
| 3006 | What should be the daily coffee intake? |
| 2673 | Coffee consuming amount |
| 447 | What's the minimum recommended age for drinking a coffee? |
| 3591 | Minimum amount of water in coffee |
| 3200 | Merits & demerits of coffee consumption |
| 208 | How many cups of coffee is it safe to consume per day? |
| 3218 | How do I vary between how much froth for each coffee drink? |
| 3002 | How much caffeine delivered by eating coffee grounds |
The “Vocabulary Mismatch” Problem
What is the maximum coffee consumption?
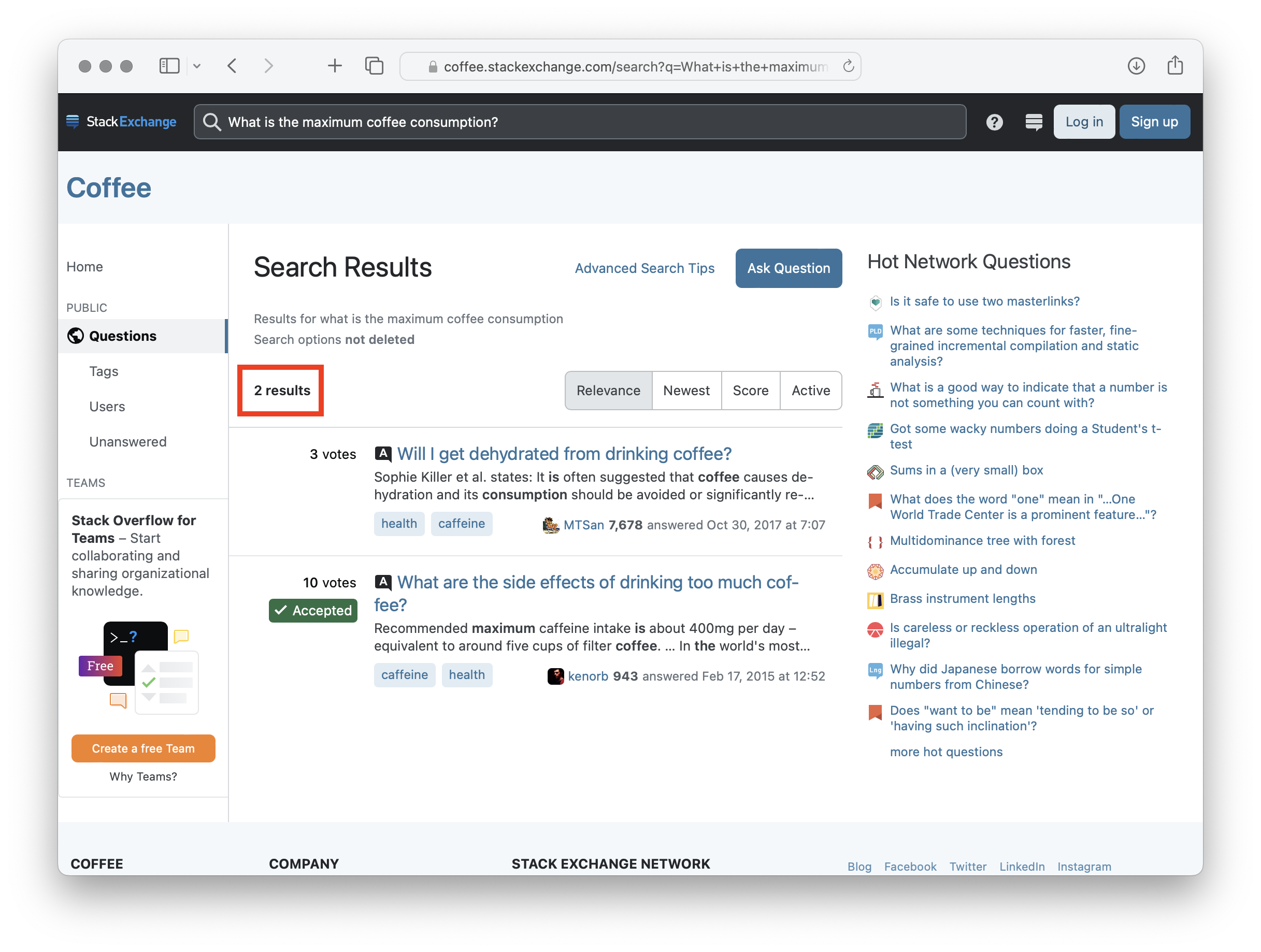
➋ Semantic search
Search in a Different Language
➋ Semantic search
CPU times: user 15 ms, sys: 3.24 ms, total: 18.2 ms
Wall time: 16 ms| text | |
|---|---|
| 208 | How many cups of coffee is it safe to consume per day? |
| 3006 | What should be the daily coffee intake? |
| 1686 | What is the limit to the amount of coffee one can consume? |
| 2270 | How much "coffee" is there in my cup? |
| 792 | Coffee on daily basis |
| 2673 | Coffee consuming amount |
| 4424 | How much coffee is too much? |
| 3218 | How do I vary between how much froth for each coffee drink? |
| 4353 | How Much Caffeine is Really in Your Coffee? - analysis / questions |
| 1073 | How many milligrams of caffeine are in a fresh coffee bean? |
Vector Databases
![]() PostgreSQL (with
PostgreSQL (with pgvector)![]() Elasticsearch
Elasticsearch![]() Redis
Redis![]() Pinecone,
Pinecone, ![]() Weviate,
Weviate, ![]() Vespa,
Vespa, ![]() Milvus, …
Milvus, …
➋ Semantic search
➌ Embeddings for other media
The LAION dataset
- More than 2 billions of image/caption pairs
- A “multi-modal” dataset
- Embeddings with the CLIP model by OpenAI
- Full size: 6.2TB
(…) ensure you have at least 20TB of disk space available
https://clickhouse.com/blog/vector-search-clickhouse-p2
➌ Embeddings for other media
Let’s download just one file from the dataset.
https://huggingface.co/datasets/laion/laion2b-en-vit-l-14-embeddings
➌ Embeddings for other media
import os
import humanize
import requests
DOWNLOAD_PATH = os.path.expanduser("~/Downloads")
BASE_URL = "https://huggingface.co/datasets/laion/laion2b-en-vit-l-14-embeddings/resolve/main"
filenames = {
"metadata": "metadata/metadata_0000.parquet",
"image_emb": "img_emb/img_emb_0000.npy",
"text_emb": "text_emb/text_emb_0000.npy",
}
for (key, filename) in filenames.items():
url = f"{BASE_URL}/{filename}"
filepath = os.path.join(DOWNLOAD_PATH, os.path.basename(filename))
filebasename = os.path.basename(filename)
if os.path.exists(filepath):
filesize = os.path.getsize(filepath)
print(f"Skipping download, file {filepath} already exists ({humanize.naturalsize(filesize)})")
else:
response = requests.get(url, stream=True)
response.raise_for_status()
total_size= int(response.headers.get('content-length', 0))
progress_bar = tqdm(desc=filebasename, total=total_size, unit='iB', unit_scale=True)
with open(filepath, "wb") as f:
try:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
progress_bar.update(len(chunk))
f.write(chunk)
except KeyboardInterrupt:
print(f"Downloading of [{filebasename}] interrupted.")
else:
filesize = os.path.getsize(filepath)
print(f"Downloaded {filepath} ({humanize.naturalsize(filesize)})")Skipping download, file /Users/karmi/Downloads/metadata_0000.parquet already exists (194.8 MB)
Skipping download, file /Users/karmi/Downloads/img_emb_0000.npy already exists (1.4 GB)
Skipping download, file /Users/karmi/Downloads/text_emb_0000.npy already exists (1.4 GB)Let’s peek inside the dataset.
➌ Embeddings for other media
pd.set_option("display.max_colwidth", 50)
df = pd.read_parquet(os.path.join(DOWNLOAD_PATH, os.path.basename(filenames["metadata"])))
df[["caption", "url", "exif"]].head(3)| caption | url | exif | |
|---|---|---|---|
| 0 | Color version PULP FICTION alternative poster art | http://cdn.shopify.com/s/files/1/0282/0804/pro... | {"Image Orientation": "Horizontal (normal)", "... |
| 1 | Writing A Successful Cover Letter by Cover Let... | http://tse3.mm.bing.net/th?id=OIP.hRMwYK1PG9pk... | {} |
| 2 | Original Herrnhut plastic star, ORANGE (Specia... | https://cdn.shopify.com/s/files/1/0600/1993/pr... | {} |
Let’s display the images.
➌ Embeddings for other media




Let’s load the image embeddings and initialize the model.
![]()
sentence-transformers/clip-ViT-L-14
➌ Embeddings for other media
from html import escape
def display_results(df, query, indices, **kwargs):
width = kwargs.get("width", 200)
df_res = pd.DataFrame({
"image": [
f"<img src='{df.url[i]}' title='{escape(df.caption[i])}' width='{width}px' onerror='this.onerror=null;this.src=\"https://placehold.co/400x400?text=Missing\"'>"
for i in indices.flatten() ],
"caption": [
df["caption"][i]
for i in indices.flatten() ],
})
return HTML(
"".join([
f"<figure style='width: {width}px'>{item.image}<figcaption>{item.caption}</figcaption></figure>"
for item in df_res.itertuples() ]))Let’s query the dataset.
A “cross-modality” search: searching image embeddings with text embeddings.
➌ Embeddings for other media
query = "cat dog pizza coffee asymptomatic"
from sklearn.neighbors import NearestNeighbors
NUM_RESULTS = 10
nn = NearestNeighbors(n_neighbors=NUM_RESULTS, algorithm="auto")
nn.fit(image_embeddings)
# Search *image* embeddings with *text* embeddings
query_embedding = np.array([model3.encode(query)])
distances, indices = nn.kneighbors(query_embedding)
display_results(df, query, indices)Let’s query the dataset.









Let’s query the dataset with a picture.

import requests
import PIL
image_url = "https://images.unsplash.com/photo-1425913397330-cf8af2ff40a1?w=600"
image = PIL.Image.open(
requests.get(image_url, stream=True).raw
)
# Search *image* embeddings with *image* embeddings
query_image_embedding = model3.encode([image])
distances, indices = nn.kneighbors(query_image_embedding)
display_results(df, "Image", indices, width=400)➌ Embeddings for other media










Embeddings for … smells?
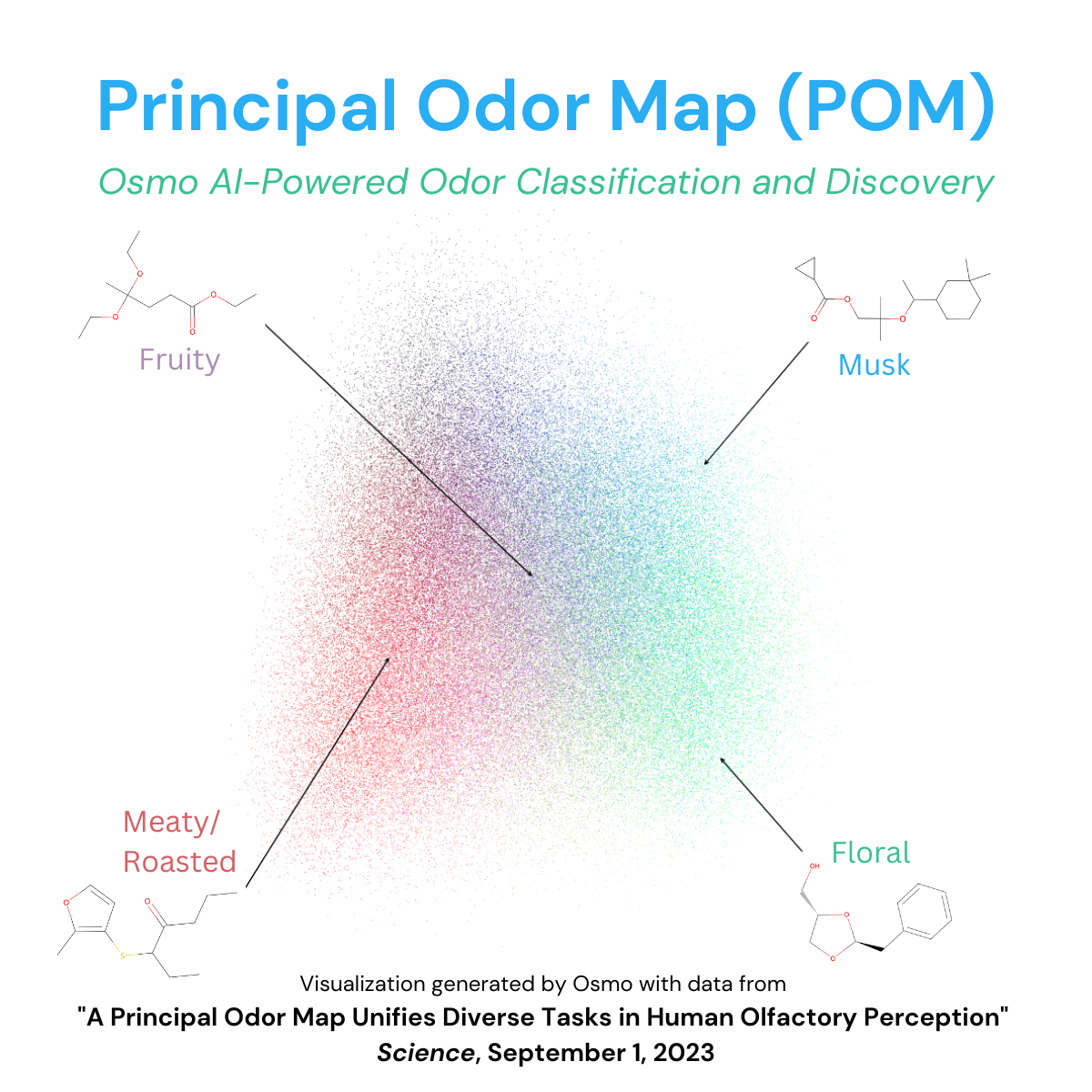
- A graph neural network
- A model that maps chemical structure to odor descriptors (256 dimensions)
- Trained on a dataset of over 5,000 molecules from fragrance industry
- Achieves human-level reliability in describing odors
https://www.osmo.ai https://doi.org/10.1101/2022.09.01.504602
Thank you!

Made with Quarto
One more thing…
Training a tiny transformer model
Training a tiny transformer model
nanoGPTby Andrej Karpathy- Implementation:
model.py,train.py,sample.py - Training:
data/shakespeare_char,config/train_shakespeare_char.py - All ~ 850 LOC
- NYT: “Watch an A.I. Learn to Write by Reading Nothing but …”
➍ Training a tiny transformer model
Let’s clone the repository…
➍ Training a tiny transformer model
! [ -d 'tmp/nanoGPT' ] || \
git clone -q 'https://github.com/karmi/nanoGPT.git' -b config_python_peps 'tmp/nanoGPT'
! tree --filesfirst 'tmp/nanoGPT'tmp/nanoGPT
├── LICENSE
├── README.md
├── bench.py
├── configurator.py
├── model.py
├── sample.py
├── scaling_laws.ipynb
├── train.py
├── transformer_sizing.ipynb
├── assets
│ ├── gpt2_124M_loss.png
│ └── nanogpt.jpg
├── config
│ ├── eval_gpt2.py
│ ├── eval_gpt2_large.py
│ ├── eval_gpt2_medium.py
│ ├── eval_gpt2_xl.py
│ ├── finetune_python_peps.py
│ ├── finetune_shakespeare.py
│ ├── train_gpt2.py
│ ├── train_python_peps_char.py
│ └── train_shakespeare_char.py
└── data
├── openwebtext
│ ├── prepare.py
│ └── readme.md
├── python_peps
│ └── prepare.py
├── python_peps_char
│ └── prepare.py
├── shakespeare
│ ├── prepare.py
│ └── readme.md
└── shakespeare_char
├── prepare.py
└── readme.md
8 directories, 28 filesLet’s download and prepare the data…
➍ Training a tiny transformer model
Downloaded ZIP to /var/folders/n8/vs92rw8d3z53yxqcfvt9nk9m0000gn/T/tmprjg5wt9q
Extracted content to /var/folders/n8/vs92rw8d3z53yxqcfvt9nk9m0000gn/T/tmp738t2vmv
length of dataset in characters: 10,824,592
all the unique characters:
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~ ¢§®°±µ½ÅÉ×Øßàáäåçèéíïñóöøúü裳ňšżƛƴʻ̴̷̡̧̨̛̗̘̙̜̝̞̟̣̤̦̩̪̫̬̭̮̯̲̹̺̻̼͇͈͉͍͎̀̂̃̄̆̇̉̊̍̏̒̓̔̽̾̿͆ͅ͏͓͔͙͚͐͑͒͗ͤͥͧͨͩͮͯ͜͢͠͡ΒάαβγεοπτВДНСабвеиклмнорстуцяѕאךערةقمي٥߅৪୨௫ḚṮἤ–—‘’“”…ⁿℂℌℕℙ™℮→∀∃∅≈⊗⋅⌁⌚⒯─│┌┐└┘┬┴╌☂☃☺♨⚛✎✒✓⧟⬛スパム十大学屆年日曜月槀櫰波激火筑粹羔鈩fi>n¥�𝐧𝘯🐱
vocab size: 323
train has 9,742,132 tokens
val has 1,082,460 tokensLet’s run the training for 100 iterations…
Replace the mps device with cuda or cpu when not running on Apple M1/M2 hardware.
➍ Training a tiny transformer model
! (cd 'tmp/nanoGPT' && \
python3 train.py 'config/train_python_peps_char.py' \
--device=mps --compile=False \
--max_iters=100 --log_interval=10 --eval_interval=10 \
--block_size=128 --batch_size=12 )Overriding config with config/train_python_peps_char.py:
# train a miniature character-level model based on Python PEPs
# https://peps.python.org/pep-0001/
out_dir = "out-python-peps-char"
eval_interval = 100
eval_iters = 20
log_interval = 1
# we expect to overfit on this small dataset, so only save when val improves
always_save_checkpoint = False
wandb_log = False # override via command line if you like
wandb_project = "python-peps-char"
wandb_run_name = None
dataset = "python_peps_char"
gradient_accumulation_steps = 1
batch_size = 64
block_size = 256 # context of up to 256 previous characters
# baby GPT model :)
n_layer = 6
n_head = 6
n_embd = 384
dropout = 0.2
learning_rate = 1e-3 # with baby networks can afford to go a bit higher
max_iters = 5000
lr_decay_iters = max_iters # make equal to max_iters usually
min_lr = 1e-4 # learning_rate / 10 usually
beta2 = 0.99 # make a bit bigger because number of tokens per iter is small
warmup_iters = 0 # not super necessary potentially
# on macbook also add
# device = 'mps' # run on MPS (https://github.com/karpathy/nanoGPT/issues/28)
# compile = False # do not torch compile the model
Overriding: device = mps
Overriding: compile = False
Overriding: max_iters = 100
Overriding: log_interval = 10
Overriding: eval_interval = 10
Overriding: block_size = 128
Overriding: batch_size = 12
tokens per iteration will be: 1,536
found vocab_size = 323 (inside data/python_peps_char/meta.pkl)
Initializing a new model from scratch
number of parameters: 10.75M
/opt/homebrew/lib/python3.11/site-packages/torch/cuda/amp/grad_scaler.py:120: UserWarning: torch.cuda.amp.GradScaler is enabled, but CUDA is not available. Disabling.
warnings.warn("torch.cuda.amp.GradScaler is enabled, but CUDA is not available. Disabling.")
num decayed parameter tensors: 26, with 10,790,016 parameters
num non-decayed parameter tensors: 13, with 4,992 parameters
using fused AdamW: False
step 0: train loss 5.7881, val loss 5.7859
iter 0: loss 5.8206, time 2051.09ms, mfu -100.00%
step 10: train loss 3.4102, val loss 3.4164
saving checkpoint to out-python-peps-char
iter 10: loss 3.2577, time 2073.89ms, mfu 0.02%
step 20: train loss 3.3962, val loss 3.4160
saving checkpoint to out-python-peps-char
iter 20: loss 3.5071, time 2063.53ms, mfu 0.02%
step 30: train loss 3.2524, val loss 3.2869
saving checkpoint to out-python-peps-char
iter 30: loss 3.2609, time 2075.96ms, mfu 0.02%
step 40: train loss 3.1787, val loss 3.1473
saving checkpoint to out-python-peps-char
iter 40: loss 3.1098, time 2068.78ms, mfu 0.02%
step 50: train loss 3.0840, val loss 3.0892
saving checkpoint to out-python-peps-char
iter 50: loss 3.0965, time 2068.53ms, mfu 0.02%
step 60: train loss 3.0588, val loss 3.0387
saving checkpoint to out-python-peps-char
iter 60: loss 2.8480, time 2037.31ms, mfu 0.02%
step 70: train loss 2.9941, val loss 2.9716
saving checkpoint to out-python-peps-char
iter 70: loss 3.0581, time 2063.60ms, mfu 0.02%
step 80: train loss 2.9373, val loss 2.9428
saving checkpoint to out-python-peps-char
iter 80: loss 2.9166, time 2058.22ms, mfu 0.02%
step 90: train loss 2.8879, val loss 2.9092
saving checkpoint to out-python-peps-char
iter 90: loss 2.9189, time 2056.94ms, mfu 0.02%
step 100: train loss 2.8599, val loss 2.8568
saving checkpoint to out-python-peps-char
iter 100: loss 2.8701, time 2097.65ms, mfu 0.02%Let’s try the output…
➍ Training a tiny transformer model
! (cd 'tmp/nanoGPT' && \
python3 sample.py \
--out_dir=out-python-peps-char \
--num_samples=1 \
--max_new_tokens=500 \
--device=cpu \
--seed="$(date +%s)" \
--start='A good Python code is ')Overriding: out_dir = out-python-peps-char
Overriding: num_samples = 1
Overriding: max_new_tokens = 500
Overriding: device = cpu
Overriding: seed = 1694413979
Overriding: start = A good Python code is
number of parameters: 10.75M
Loading meta from data/python_peps_char/meta.pkl...
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
A good Python code is finmos atrerenalar.-sputhe bdinaxlyfas ano e be te gemenob enguorpllethenenmen osul minnle ad en thexbkerpos n x[ ter
s fe otife l
nnps ausyne ans. then at/roosptoorad f me-pesico g orar us nutheps, thitit._P anin bsesenenos tet.
.
dicor ance t
. lenesints bef sitatsere si onotanf t d b bincedesefarn t a m e vacjowo lale nurerat4 onor age e anise g mr be onthe-xp an nacof ted tatandasiblarodorong i thndhan leron canserinin herd plin fon anatenanpathef s rithere Ghucotos d tiyronsedur t...
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~Let’s continue the training for 1000 iterations…
➍ Training a tiny transformer model
! (cd 'tmp/nanoGPT' && \
python3 train.py 'config/train_python_peps_char.py' \
--device=mps --compile=False \
--max_iters=1000 --eval_interval=100 --log_interval=10 \
--block_size=128 --batch_size=12 \
--init_from='resume')Overriding config with config/train_python_peps_char.py:
# train a miniature character-level model based on Python PEPs
# https://peps.python.org/pep-0001/
out_dir = "out-python-peps-char"
eval_interval = 100
eval_iters = 20
log_interval = 1
# we expect to overfit on this small dataset, so only save when val improves
always_save_checkpoint = False
wandb_log = False # override via command line if you like
wandb_project = "python-peps-char"
wandb_run_name = None
dataset = "python_peps_char"
gradient_accumulation_steps = 1
batch_size = 64
block_size = 256 # context of up to 256 previous characters
# baby GPT model :)
n_layer = 6
n_head = 6
n_embd = 384
dropout = 0.2
learning_rate = 1e-3 # with baby networks can afford to go a bit higher
max_iters = 5000
lr_decay_iters = max_iters # make equal to max_iters usually
min_lr = 1e-4 # learning_rate / 10 usually
beta2 = 0.99 # make a bit bigger because number of tokens per iter is small
warmup_iters = 0 # not super necessary potentially
# on macbook also add
# device = 'mps' # run on MPS (https://github.com/karpathy/nanoGPT/issues/28)
# compile = False # do not torch compile the model
Overriding: device = mps
Overriding: compile = False
Overriding: max_iters = 1000
Overriding: eval_interval = 100
Overriding: log_interval = 10
Overriding: block_size = 128
Overriding: batch_size = 12
Overriding: init_from = resume
tokens per iteration will be: 1,536
found vocab_size = 323 (inside data/python_peps_char/meta.pkl)
Resuming training from out-python-peps-char
number of parameters: 10.75M
/opt/homebrew/lib/python3.11/site-packages/torch/cuda/amp/grad_scaler.py:120: UserWarning: torch.cuda.amp.GradScaler is enabled, but CUDA is not available. Disabling.
warnings.warn("torch.cuda.amp.GradScaler is enabled, but CUDA is not available. Disabling.")
num decayed parameter tensors: 26, with 10,790,016 parameters
num non-decayed parameter tensors: 13, with 4,992 parameters
using fused AdamW: False
step 100: train loss 2.8493, val loss 2.8981
iter 100: loss 3.1073, time 2046.86ms, mfu -100.00%
iter 110: loss 2.8265, time 159.36ms, mfu 0.21%
iter 120: loss 2.9178, time 158.76ms, mfu 0.21%
iter 130: loss 3.0910, time 158.29ms, mfu 0.21%
iter 140: loss 2.7329, time 153.66ms, mfu 0.21%
iter 150: loss 2.7806, time 154.46ms, mfu 0.21%
iter 160: loss 2.8659, time 156.52ms, mfu 0.21%
iter 170: loss 2.7454, time 160.12ms, mfu 0.21%
iter 180: loss 2.7229, time 160.91ms, mfu 0.21%
iter 190: loss 2.7062, time 157.70ms, mfu 0.21%
step 200: train loss 2.7405, val loss 2.7242
saving checkpoint to out-python-peps-char
iter 200: loss 2.7714, time 2047.83ms, mfu 0.19%
iter 210: loss 2.9391, time 155.69ms, mfu 0.19%
iter 220: loss 2.7786, time 159.49ms, mfu 0.20%
iter 230: loss 2.5624, time 160.60ms, mfu 0.20%
iter 240: loss 2.8867, time 155.25ms, mfu 0.20%
iter 250: loss 2.6296, time 155.96ms, mfu 0.20%
iter 260: loss 2.6903, time 160.19ms, mfu 0.20%
iter 270: loss 2.6721, time 157.93ms, mfu 0.20%
iter 280: loss 2.7015, time 158.63ms, mfu 0.20%
iter 290: loss 2.8002, time 155.70ms, mfu 0.20%
step 300: train loss 2.6667, val loss 2.7120
saving checkpoint to out-python-peps-char
iter 300: loss 2.9318, time 2085.57ms, mfu 0.19%
iter 310: loss 2.7656, time 157.16ms, mfu 0.19%
iter 320: loss 2.7524, time 155.57ms, mfu 0.19%
iter 330: loss 2.8231, time 153.63ms, mfu 0.19%
iter 340: loss 2.6844, time 154.04ms, mfu 0.20%
iter 350: loss 2.6755, time 159.30ms, mfu 0.20%
iter 360: loss 2.6727, time 154.88ms, mfu 0.20%
iter 370: loss 2.6401, time 158.10ms, mfu 0.20%
iter 380: loss 2.5010, time 155.52ms, mfu 0.20%
iter 390: loss 2.5265, time 156.44ms, mfu 0.20%
step 400: train loss 2.6272, val loss 2.6283
saving checkpoint to out-python-peps-char
iter 400: loss 2.6528, time 2061.84ms, mfu 0.18%
iter 410: loss 2.6632, time 157.79ms, mfu 0.19%
iter 420: loss 2.6937, time 156.75ms, mfu 0.19%
iter 430: loss 2.3994, time 156.39ms, mfu 0.19%
iter 440: loss 2.6321, time 161.98ms, mfu 0.19%
iter 450: loss 2.5794, time 160.79ms, mfu 0.20%
iter 460: loss 2.5512, time 157.49ms, mfu 0.20%
iter 470: loss 2.6617, time 157.31ms, mfu 0.20%
iter 480: loss 2.5715, time 158.38ms, mfu 0.20%
iter 490: loss 2.6151, time 159.02ms, mfu 0.20%
step 500: train loss 2.6002, val loss 2.6242
saving checkpoint to out-python-peps-char
iter 500: loss 2.5579, time 2069.60ms, mfu 0.18%
iter 510: loss 2.6138, time 157.67ms, mfu 0.19%
iter 520: loss 2.5819, time 159.96ms, mfu 0.19%
iter 530: loss 2.6238, time 158.65ms, mfu 0.19%
iter 540: loss 2.6576, time 159.97ms, mfu 0.19%
iter 550: loss 2.4655, time 159.78ms, mfu 0.19%
iter 560: loss 2.6956, time 157.31ms, mfu 0.20%
iter 570: loss 2.4883, time 160.03ms, mfu 0.20%
iter 580: loss 2.5292, time 156.90ms, mfu 0.20%
iter 590: loss 2.7204, time 160.22ms, mfu 0.20%
step 600: train loss 2.6054, val loss 2.5751
saving checkpoint to out-python-peps-char
iter 600: loss 2.6876, time 2079.26ms, mfu 0.18%
iter 610: loss 2.6970, time 160.55ms, mfu 0.18%
iter 620: loss 2.5635, time 159.51ms, mfu 0.19%
iter 630: loss 2.5722, time 159.64ms, mfu 0.19%
iter 640: loss 2.6576, time 159.29ms, mfu 0.19%
iter 650: loss 2.6629, time 158.75ms, mfu 0.19%
iter 660: loss 2.4561, time 160.27ms, mfu 0.19%
iter 670: loss 2.5355, time 159.05ms, mfu 0.20%
iter 680: loss 2.6293, time 157.54ms, mfu 0.20%
iter 690: loss 2.4230, time 161.01ms, mfu 0.20%
step 700: train loss 2.5462, val loss 2.5384
saving checkpoint to out-python-peps-char
iter 700: loss 2.5740, time 2065.55ms, mfu 0.18%
iter 710: loss 2.4509, time 156.57ms, mfu 0.18%
iter 720: loss 2.6919, time 157.44ms, mfu 0.19%
iter 730: loss 2.4529, time 160.13ms, mfu 0.19%
iter 740: loss 2.6126, time 151.79ms, mfu 0.19%
iter 750: loss 2.6207, time 152.63ms, mfu 0.19%
iter 760: loss 2.3668, time 159.03ms, mfu 0.20%
iter 770: loss 2.5513, time 159.26ms, mfu 0.20%
iter 780: loss 2.5633, time 157.27ms, mfu 0.20%
iter 790: loss 2.4206, time 159.83ms, mfu 0.20%
step 800: train loss 2.4368, val loss 2.4322
saving checkpoint to out-python-peps-char
iter 800: loss 2.4541, time 2080.52ms, mfu 0.18%
iter 810: loss 2.4992, time 156.59ms, mfu 0.19%
iter 820: loss 2.5003, time 156.95ms, mfu 0.19%
iter 830: loss 2.4490, time 159.98ms, mfu 0.19%
iter 840: loss 2.4964, time 155.40ms, mfu 0.19%
iter 850: loss 2.4557, time 155.21ms, mfu 0.19%
iter 860: loss 2.5860, time 161.07ms, mfu 0.20%
iter 870: loss 2.4550, time 159.33ms, mfu 0.20%
iter 880: loss 2.4199, time 160.35ms, mfu 0.20%
iter 890: loss 2.5686, time 157.15ms, mfu 0.20%
step 900: train loss 2.3250, val loss 2.3649
saving checkpoint to out-python-peps-char
iter 900: loss 2.4752, time 2063.28ms, mfu 0.18%
iter 910: loss 2.4306, time 159.17ms, mfu 0.18%
iter 920: loss 2.3784, time 159.83ms, mfu 0.19%
iter 930: loss 2.3465, time 158.60ms, mfu 0.19%
iter 940: loss 2.3496, time 160.31ms, mfu 0.19%
iter 950: loss 2.2669, time 160.17ms, mfu 0.19%
iter 960: loss 2.3639, time 160.37ms, mfu 0.19%
iter 970: loss 2.3838, time 156.35ms, mfu 0.20%
iter 980: loss 2.3694, time 159.58ms, mfu 0.20%
iter 990: loss 2.3414, time 160.78ms, mfu 0.20%
step 1000: train loss 2.2963, val loss 2.3054
saving checkpoint to out-python-peps-char
iter 1000: loss 2.3887, time 2068.74ms, mfu 0.18%… and let’s try the output again.
➍ Training a tiny transformer model
! (cd 'tmp/nanoGPT' && \
python3 sample.py \
--out_dir=out-python-peps-char \
--num_samples=1 \
--max_new_tokens=500 \
--device=cpu \
--seed="$(date +%s)" \
--start='A good Python code is ')Overriding: out_dir = out-python-peps-char
Overriding: num_samples = 1
Overriding: max_new_tokens = 500
Overriding: device = cpu
Overriding: seed = 1694414209
Overriding: start = A good Python code is
number of parameters: 10.75M
Loading meta from data/python_peps_char/meta.pkl...
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
A good Python code is cons cons Loutimian be taluple binte a
-------------
A cary is is and the to pron the the kally en norcly extectse fin of vally.
N the thin-ch the pes it the wilosimpor fore``` in cle of to denc: on of ` are birerm typeppvas the pocking the vablort ancat_telle```` mef.
-Worf the st `````__Explernclomplect exate ford alltion is to mers etuto ar Gat wsit the ust suctionche ther an
for con cas ` onctize por seas usupor she inaction
de the cover peveg rarnt is of din as ave cal `````````` all...
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~Let’s run 5000 iterations…
➍ Training a tiny transformer model
! (cd 'tmp/nanoGPT' && \
python3 train.py 'config/train_python_peps_char.py' \
--device=mps --compile=False \
--max_iters=5000 --eval_interval=100 --log_interval=10 \
--block_size=128 --batch_size=12 \
--init_from='resume')Overriding config with config/train_python_peps_char.py:
# train a miniature character-level model based on Python PEPs
# https://peps.python.org/pep-0001/
out_dir = "out-python-peps-char"
eval_interval = 100
eval_iters = 20
log_interval = 1
# we expect to overfit on this small dataset, so only save when val improves
always_save_checkpoint = False
wandb_log = False # override via command line if you like
wandb_project = "python-peps-char"
wandb_run_name = None
dataset = "python_peps_char"
gradient_accumulation_steps = 1
batch_size = 64
block_size = 256 # context of up to 256 previous characters
# baby GPT model :)
n_layer = 6
n_head = 6
n_embd = 384
dropout = 0.2
learning_rate = 1e-3 # with baby networks can afford to go a bit higher
max_iters = 5000
lr_decay_iters = max_iters # make equal to max_iters usually
min_lr = 1e-4 # learning_rate / 10 usually
beta2 = 0.99 # make a bit bigger because number of tokens per iter is small
warmup_iters = 0 # not super necessary potentially
# on macbook also add
# device = 'mps' # run on MPS (https://github.com/karpathy/nanoGPT/issues/28)
# compile = False # do not torch compile the model
Overriding: device = mps
Overriding: compile = False
Overriding: max_iters = 5000
Overriding: eval_interval = 100
Overriding: log_interval = 10
Overriding: block_size = 128
Overriding: batch_size = 12
Overriding: init_from = resume
tokens per iteration will be: 1,536
found vocab_size = 323 (inside data/python_peps_char/meta.pkl)
Resuming training from out-python-peps-char
number of parameters: 10.75M
/opt/homebrew/lib/python3.11/site-packages/torch/cuda/amp/grad_scaler.py:120: UserWarning: torch.cuda.amp.GradScaler is enabled, but CUDA is not available. Disabling.
warnings.warn("torch.cuda.amp.GradScaler is enabled, but CUDA is not available. Disabling.")
num decayed parameter tensors: 26, with 10,790,016 parameters
num non-decayed parameter tensors: 13, with 4,992 parameters
using fused AdamW: False
step 1000: train loss 2.2751, val loss 2.3217
iter 1000: loss 2.5321, time 2033.84ms, mfu -100.00%
iter 1010: loss 2.2959, time 159.70ms, mfu 0.21%
iter 1020: loss 2.3953, time 158.09ms, mfu 0.21%
iter 1030: loss 2.5974, time 161.79ms, mfu 0.21%
iter 1040: loss 2.2316, time 157.27ms, mfu 0.21%
iter 1050: loss 2.2440, time 156.76ms, mfu 0.21%
iter 1060: loss 2.3252, time 156.65ms, mfu 0.21%
iter 1070: loss 2.2575, time 160.99ms, mfu 0.21%
iter 1080: loss 2.2046, time 161.03ms, mfu 0.21%
iter 1090: loss 2.3116, time 163.34ms, mfu 0.21%
step 1100: train loss 2.2272, val loss 2.1941
saving checkpoint to out-python-peps-char
iter 1100: loss 2.3039, time 2091.49ms, mfu 0.19%
iter 1110: loss 2.4511, time 159.44ms, mfu 0.19%
iter 1120: loss 2.3735, time 160.46ms, mfu 0.19%
iter 1130: loss 2.0979, time 161.30ms, mfu 0.20%
iter 1140: loss 2.3787, time 160.13ms, mfu 0.20%
iter 1150: loss 2.1693, time 161.58ms, mfu 0.20%
iter 1160: loss 2.2239, time 160.76ms, mfu 0.20%
iter 1170: loss 2.2148, time 161.68ms, mfu 0.20%
iter 1180: loss 2.2410, time 158.69ms, mfu 0.20%
iter 1190: loss 2.3768, time 164.45ms, mfu 0.20%
step 1200: train loss 2.1342, val loss 2.1694
saving checkpoint to out-python-peps-char
iter 1200: loss 2.5234, time 2112.01ms, mfu 0.18%
iter 1210: loss 2.2162, time 159.61ms, mfu 0.19%
iter 1220: loss 2.2980, time 159.95ms, mfu 0.19%
iter 1230: loss 2.3325, time 161.26ms, mfu 0.19%
iter 1240: loss 2.2036, time 161.14ms, mfu 0.19%
iter 1250: loss 2.2108, time 161.39ms, mfu 0.19%
iter 1260: loss 2.2324, time 157.18ms, mfu 0.20%
iter 1270: loss 2.1259, time 157.28ms, mfu 0.20%
iter 1280: loss 2.0822, time 161.55ms, mfu 0.20%
iter 1290: loss 2.0488, time 163.20ms, mfu 0.20%
step 1300: train loss 2.0907, val loss 2.1053
saving checkpoint to out-python-peps-char
iter 1300: loss 2.1816, time 2099.70ms, mfu 0.18%
iter 1310: loss 2.2082, time 161.58ms, mfu 0.18%
iter 1320: loss 2.2260, time 163.80ms, mfu 0.19%
iter 1330: loss 1.9390, time 164.23ms, mfu 0.19%
iter 1340: loss 2.1417, time 165.60ms, mfu 0.19%
iter 1350: loss 2.1275, time 163.67ms, mfu 0.19%
iter 1360: loss 2.1526, time 165.04ms, mfu 0.19%
iter 1370: loss 2.1847, time 163.83ms, mfu 0.19%
iter 1380: loss 2.1439, time 164.30ms, mfu 0.19%
iter 1390: loss 2.1694, time 163.08ms, mfu 0.19%
step 1400: train loss 2.0535, val loss 2.0741
saving checkpoint to out-python-peps-char
iter 1400: loss 2.0581, time 2101.24ms, mfu 0.18%
iter 1410: loss 2.1750, time 162.06ms, mfu 0.18%
iter 1420: loss 2.1577, time 163.56ms, mfu 0.18%
iter 1430: loss 2.0761, time 164.24ms, mfu 0.18%
iter 1440: loss 2.1740, time 163.36ms, mfu 0.19%
iter 1450: loss 1.9313, time 164.91ms, mfu 0.19%
iter 1460: loss 2.2576, time 162.13ms, mfu 0.19%
iter 1470: loss 1.9881, time 164.06ms, mfu 0.19%
iter 1480: loss 2.0822, time 169.61ms, mfu 0.19%
iter 1490: loss 2.2081, time 168.85ms, mfu 0.19%
step 1500: train loss 2.0382, val loss 2.0223
saving checkpoint to out-python-peps-char
iter 1500: loss 2.2091, time 2107.37ms, mfu 0.18%
iter 1510: loss 2.2030, time 162.18ms, mfu 0.18%
iter 1520: loss 2.0815, time 164.80ms, mfu 0.18%
iter 1530: loss 1.9971, time 168.94ms, mfu 0.18%
iter 1540: loss 2.1914, time 163.79ms, mfu 0.18%
iter 1550: loss 2.1675, time 164.10ms, mfu 0.19%
iter 1560: loss 1.9964, time 164.74ms, mfu 0.19%
iter 1570: loss 2.0627, time 163.78ms, mfu 0.19%
iter 1580: loss 2.1765, time 164.61ms, mfu 0.19%
iter 1590: loss 1.9497, time 161.92ms, mfu 0.19%
step 1600: train loss 1.9919, val loss 1.9822
saving checkpoint to out-python-peps-char
iter 1600: loss 2.0485, time 2123.05ms, mfu 0.18%
iter 1610: loss 2.0262, time 162.55ms, mfu 0.18%
iter 1620: loss 2.2110, time 167.26ms, mfu 0.18%
iter 1630: loss 1.9454, time 164.23ms, mfu 0.18%
iter 1640: loss 2.1486, time 164.16ms, mfu 0.18%
iter 1650: loss 2.1516, time 164.55ms, mfu 0.19%
iter 1660: loss 1.9299, time 164.44ms, mfu 0.19%
iter 1670: loss 2.0477, time 165.66ms, mfu 0.19%
iter 1680: loss 2.0975, time 166.43ms, mfu 0.19%
iter 1690: loss 1.9842, time 166.54ms, mfu 0.19%
step 1700: train loss 1.9301, val loss 1.9373
saving checkpoint to out-python-peps-char
iter 1700: loss 1.9992, time 2134.01ms, mfu 0.17%
iter 1710: loss 2.0447, time 163.00ms, mfu 0.18%
iter 1720: loss 2.0757, time 167.05ms, mfu 0.18%
iter 1730: loss 2.0395, time 165.84ms, mfu 0.18%
iter 1740: loss 2.0162, time 166.06ms, mfu 0.18%
iter 1750: loss 1.9759, time 165.70ms, mfu 0.19%
iter 1760: loss 2.1395, time 165.43ms, mfu 0.19%
iter 1770: loss 2.0391, time 158.29ms, mfu 0.19%
iter 1780: loss 1.9806, time 163.78ms, mfu 0.19%
iter 1790: loss 2.1135, time 167.92ms, mfu 0.19%
step 1800: train loss 1.8766, val loss 1.9167
saving checkpoint to out-python-peps-char
iter 1800: loss 2.0355, time 2107.03ms, mfu 0.17%
iter 1810: loss 2.0390, time 155.03ms, mfu 0.18%
iter 1820: loss 2.0104, time 166.09ms, mfu 0.18%
iter 1830: loss 1.9560, time 164.62ms, mfu 0.18%
iter 1840: loss 2.0396, time 166.15ms, mfu 0.19%
iter 1850: loss 1.9310, time 164.93ms, mfu 0.19%
iter 1860: loss 1.9971, time 166.84ms, mfu 0.19%
iter 1870: loss 1.9659, time 165.48ms, mfu 0.19%
iter 1880: loss 1.9533, time 162.90ms, mfu 0.19%
iter 1890: loss 1.9889, time 166.04ms, mfu 0.19%
step 1900: train loss 1.8782, val loss 1.8935
saving checkpoint to out-python-peps-char
iter 1900: loss 2.0162, time 2109.06ms, mfu 0.17%
iter 1910: loss 2.0120, time 165.15ms, mfu 0.18%
iter 1920: loss 2.1173, time 166.94ms, mfu 0.18%
iter 1930: loss 1.9274, time 163.11ms, mfu 0.18%
iter 1940: loss 1.9207, time 163.72ms, mfu 0.18%
iter 1950: loss 1.9227, time 163.95ms, mfu 0.19%
iter 1960: loss 2.1500, time 157.30ms, mfu 0.19%
iter 1970: loss 1.9999, time 164.34ms, mfu 0.19%
iter 1980: loss 1.9464, time 163.36ms, mfu 0.19%
iter 1990: loss 2.0942, time 164.16ms, mfu 0.19%
step 2000: train loss 1.8126, val loss 1.8323
saving checkpoint to out-python-peps-char
iter 2000: loss 1.9382, time 2096.49ms, mfu 0.18%
iter 2010: loss 1.8988, time 165.74ms, mfu 0.18%
iter 2020: loss 1.9780, time 166.76ms, mfu 0.18%
iter 2030: loss 2.1929, time 163.55ms, mfu 0.18%
iter 2040: loss 2.0863, time 167.38ms, mfu 0.18%
iter 2050: loss 1.9370, time 167.84ms, mfu 0.19%
iter 2060: loss 1.8958, time 165.92ms, mfu 0.19%
iter 2070: loss 1.8126, time 167.26ms, mfu 0.19%
iter 2080: loss 2.1033, time 163.03ms, mfu 0.19%
iter 2090: loss 1.9810, time 161.12ms, mfu 0.19%
step 2100: train loss 1.8147, val loss 1.8624
iter 2100: loss 1.9501, time 1903.94ms, mfu 0.17%
iter 2110: loss 1.8082, time 164.58ms, mfu 0.18%
iter 2120: loss 1.9426, time 165.68ms, mfu 0.18%
iter 2130: loss 2.1383, time 163.34ms, mfu 0.18%
iter 2140: loss 1.9970, time 166.34ms, mfu 0.18%
iter 2150: loss 2.0046, time 166.80ms, mfu 0.19%
iter 2160: loss 2.0325, time 166.42ms, mfu 0.19%
iter 2170: loss 1.8115, time 166.18ms, mfu 0.19%
iter 2180: loss 1.9505, time 163.50ms, mfu 0.19%
iter 2190: loss 1.9368, time 164.19ms, mfu 0.19%
step 2200: train loss 1.8122, val loss 1.8284
saving checkpoint to out-python-peps-char
iter 2200: loss 2.0438, time 2130.31ms, mfu 0.17%
iter 2210: loss 1.8211, time 160.78ms, mfu 0.18%
iter 2220: loss 1.8429, time 164.96ms, mfu 0.18%
iter 2230: loss 1.8908, time 165.08ms, mfu 0.18%
iter 2240: loss 1.8971, time 165.61ms, mfu 0.18%
iter 2250: loss 1.9284, time 167.34ms, mfu 0.19%
iter 2260: loss 1.7465, time 165.35ms, mfu 0.19%
iter 2270: loss 1.8372, time 166.68ms, mfu 0.19%
iter 2280: loss 1.9061, time 162.99ms, mfu 0.19%
iter 2290: loss 1.8952, time 163.61ms, mfu 0.19%
step 2300: train loss 1.7657, val loss 1.7991
saving checkpoint to out-python-peps-char
iter 2300: loss 2.0742, time 2096.83ms, mfu 0.17%
iter 2310: loss 1.8250, time 166.97ms, mfu 0.18%
iter 2320: loss 1.7708, time 164.46ms, mfu 0.18%
iter 2330: loss 1.9168, time 166.20ms, mfu 0.18%
iter 2340: loss 1.9586, time 163.30ms, mfu 0.18%
iter 2350: loss 1.7589, time 166.18ms, mfu 0.19%
iter 2360: loss 1.9428, time 168.06ms, mfu 0.19%
iter 2370: loss 1.8045, time 164.80ms, mfu 0.19%
iter 2380: loss 1.8843, time 163.61ms, mfu 0.19%
iter 2390: loss 2.0198, time 163.90ms, mfu 0.19%
step 2400: train loss 1.7510, val loss 1.7999
iter 2400: loss 1.8528, time 1904.17ms, mfu 0.17%
iter 2410: loss 1.8748, time 164.39ms, mfu 0.18%
iter 2420: loss 1.7897, time 164.89ms, mfu 0.18%
iter 2430: loss 1.7412, time 163.11ms, mfu 0.18%
iter 2440: loss 1.8162, time 164.41ms, mfu 0.18%
iter 2450: loss 1.9715, time 165.29ms, mfu 0.19%
iter 2460: loss 1.8782, time 163.82ms, mfu 0.19%
iter 2470: loss 1.9325, time 164.61ms, mfu 0.19%
iter 2480: loss 1.7956, time 164.44ms, mfu 0.19%
iter 2490: loss 1.8469, time 164.23ms, mfu 0.19%
step 2500: train loss 1.7438, val loss 1.7246
saving checkpoint to out-python-peps-char
iter 2500: loss 1.7390, time 2134.78ms, mfu 0.17%
iter 2510: loss 1.9502, time 162.77ms, mfu 0.18%
iter 2520: loss 1.8342, time 165.67ms, mfu 0.18%
iter 2530: loss 1.7282, time 166.50ms, mfu 0.18%
iter 2540: loss 1.8788, time 164.06ms, mfu 0.18%
iter 2550: loss 1.8752, time 164.71ms, mfu 0.19%
iter 2560: loss 1.8382, time 164.10ms, mfu 0.19%
iter 2570: loss 1.7344, time 162.98ms, mfu 0.19%
iter 2580: loss 1.8608, time 166.38ms, mfu 0.19%
iter 2590: loss 1.7900, time 164.99ms, mfu 0.19%
step 2600: train loss 1.7316, val loss 1.7415
iter 2600: loss 1.8116, time 1897.27ms, mfu 0.17%
iter 2610: loss 1.8210, time 164.74ms, mfu 0.18%
iter 2620: loss 1.8711, time 164.79ms, mfu 0.18%
iter 2630: loss 1.8306, time 162.46ms, mfu 0.18%
iter 2640: loss 1.7361, time 163.82ms, mfu 0.18%
iter 2650: loss 1.7243, time 163.83ms, mfu 0.19%
iter 2660: loss 1.8159, time 163.69ms, mfu 0.19%
iter 2670: loss 1.8114, time 165.92ms, mfu 0.19%
iter 2680: loss 1.8332, time 165.18ms, mfu 0.19%
iter 2690: loss 1.8311, time 165.00ms, mfu 0.19%
step 2700: train loss 1.6947, val loss 1.7094
saving checkpoint to out-python-peps-char
iter 2700: loss 1.8775, time 2120.45ms, mfu 0.17%
iter 2710: loss 1.9892, time 159.29ms, mfu 0.18%
iter 2720: loss 1.9068, time 168.33ms, mfu 0.18%
iter 2730: loss 1.8624, time 164.18ms, mfu 0.18%
iter 2740: loss 2.0804, time 164.69ms, mfu 0.18%
iter 2750: loss 1.7825, time 165.19ms, mfu 0.19%
iter 2760: loss 1.8506, time 164.88ms, mfu 0.19%
iter 2770: loss 1.8467, time 164.96ms, mfu 0.19%
iter 2780: loss 1.7341, time 163.63ms, mfu 0.19%
iter 2790: loss 1.9544, time 164.20ms, mfu 0.19%
step 2800: train loss 1.6984, val loss 1.6776
saving checkpoint to out-python-peps-char
iter 2800: loss 1.7847, time 2130.00ms, mfu 0.17%
iter 2810: loss 1.6469, time 163.73ms, mfu 0.18%
iter 2820: loss 1.6615, time 164.24ms, mfu 0.18%
iter 2830: loss 1.8137, time 164.88ms, mfu 0.18%
iter 2840: loss 1.8090, time 165.33ms, mfu 0.18%
iter 2850: loss 1.8369, time 164.53ms, mfu 0.19%
iter 2860: loss 1.7922, time 165.48ms, mfu 0.19%
iter 2870: loss 1.7941, time 165.22ms, mfu 0.19%
iter 2880: loss 1.7938, time 165.05ms, mfu 0.19%
iter 2890: loss 1.7479, time 163.64ms, mfu 0.19%
step 2900: train loss 1.6336, val loss 1.6960
iter 2900: loss 1.7545, time 1893.25ms, mfu 0.17%
iter 2910: loss 1.8330, time 164.16ms, mfu 0.18%
iter 2920: loss 1.8226, time 164.29ms, mfu 0.18%
iter 2930: loss 1.8460, time 163.23ms, mfu 0.18%
iter 2940: loss 1.7338, time 167.41ms, mfu 0.18%
iter 2950: loss 1.7633, time 164.08ms, mfu 0.19%
iter 2960: loss 1.8092, time 163.60ms, mfu 0.19%
iter 2970: loss 1.7407, time 163.96ms, mfu 0.19%
iter 2980: loss 1.8220, time 165.03ms, mfu 0.19%
iter 2990: loss 1.8005, time 166.81ms, mfu 0.19%
step 3000: train loss 1.7105, val loss 1.6684
saving checkpoint to out-python-peps-char
iter 3000: loss 1.7108, time 2129.25ms, mfu 0.17%
iter 3010: loss 1.7510, time 164.12ms, mfu 0.18%
iter 3020: loss 1.6979, time 167.62ms, mfu 0.18%
iter 3030: loss 1.7289, time 163.67ms, mfu 0.18%
iter 3040: loss 2.0497, time 163.84ms, mfu 0.18%
iter 3050: loss 1.5651, time 166.91ms, mfu 0.19%
iter 3060: loss 1.8488, time 163.34ms, mfu 0.19%
iter 3070: loss 1.7764, time 164.49ms, mfu 0.19%
iter 3080: loss 1.6803, time 162.05ms, mfu 0.19%
iter 3090: loss 1.7195, time 167.62ms, mfu 0.19%
step 3100: train loss 1.6231, val loss 1.6290
saving checkpoint to out-python-peps-char
iter 3100: loss 1.7252, time 2211.81ms, mfu 0.17%
iter 3110: loss 1.6458, time 166.28ms, mfu 0.18%
iter 3120: loss 1.7342, time 184.71ms, mfu 0.18%
iter 3130: loss 1.6939, time 195.95ms, mfu 0.18%
iter 3140: loss 1.5731, time 185.48ms, mfu 0.18%
iter 3150: loss 1.7253, time 181.55ms, mfu 0.18%
iter 3160: loss 1.6695, time 182.20ms, mfu 0.18%
iter 3170: loss 1.6104, time 192.99ms, mfu 0.18%
iter 3180: loss 1.7872, time 183.29ms, mfu 0.18%
iter 3190: loss 1.7972, time 182.51ms, mfu 0.18%
step 3200: train loss 1.5629, val loss 1.6022
saving checkpoint to out-python-peps-char
iter 3200: loss 1.6589, time 2416.18ms, mfu 0.16%
iter 3210: loss 1.6352, time 207.36ms, mfu 0.16%
iter 3220: loss 1.6786, time 161.76ms, mfu 0.17%
iter 3230: loss 1.6589, time 163.28ms, mfu 0.17%
iter 3240: loss 1.7947, time 164.05ms, mfu 0.17%
iter 3250: loss 1.5852, time 164.32ms, mfu 0.18%
iter 3260: loss 1.6043, time 162.75ms, mfu 0.18%
iter 3270: loss 1.5508, time 165.27ms, mfu 0.18%
iter 3280: loss 1.7505, time 165.98ms, mfu 0.18%
iter 3290: loss 1.7231, time 162.76ms, mfu 0.19%
step 3300: train loss 1.6104, val loss 1.5974
saving checkpoint to out-python-peps-char
iter 3300: loss 1.6592, time 2108.82ms, mfu 0.17%
iter 3310: loss 1.5303, time 165.20ms, mfu 0.17%
iter 3320: loss 1.7430, time 161.06ms, mfu 0.18%
iter 3330: loss 1.8581, time 161.36ms, mfu 0.18%
iter 3340: loss 1.6117, time 168.71ms, mfu 0.18%
iter 3350: loss 1.7177, time 158.68ms, mfu 0.18%
iter 3360: loss 1.5891, time 163.76ms, mfu 0.19%
iter 3370: loss 1.6948, time 162.09ms, mfu 0.19%
iter 3380: loss 1.7693, time 161.96ms, mfu 0.19%
iter 3390: loss 1.7800, time 160.02ms, mfu 0.19%
step 3400: train loss 1.6072, val loss 1.5938
saving checkpoint to out-python-peps-char
iter 3400: loss 1.8502, time 2099.53ms, mfu 0.17%
iter 3410: loss 1.9017, time 161.89ms, mfu 0.18%
iter 3420: loss 1.6999, time 164.67ms, mfu 0.18%
iter 3430: loss 1.7368, time 165.29ms, mfu 0.18%
iter 3440: loss 1.8204, time 161.01ms, mfu 0.18%
iter 3450: loss 1.7604, time 160.92ms, mfu 0.19%
iter 3460: loss 2.0020, time 162.01ms, mfu 0.19%
iter 3470: loss 1.6922, time 167.04ms, mfu 0.19%
iter 3480: loss 1.6569, time 160.47ms, mfu 0.19%
iter 3490: loss 1.6549, time 161.89ms, mfu 0.19%
step 3500: train loss 1.5491, val loss 1.5649
saving checkpoint to out-python-peps-char
iter 3500: loss 1.7571, time 2106.34ms, mfu 0.18%
iter 3510: loss 1.5435, time 160.65ms, mfu 0.18%
iter 3520: loss 1.7043, time 164.98ms, mfu 0.18%
iter 3530: loss 1.7491, time 165.80ms, mfu 0.18%
iter 3540: loss 1.5602, time 162.39ms, mfu 0.19%
iter 3550: loss 1.6158, time 162.54ms, mfu 0.19%
iter 3560: loss 1.8871, time 168.39ms, mfu 0.19%
iter 3570: loss 1.6485, time 162.32ms, mfu 0.19%
iter 3580: loss 1.6221, time 160.89ms, mfu 0.19%
iter 3590: loss 1.8020, time 162.11ms, mfu 0.19%
step 3600: train loss 1.5348, val loss 1.5987
iter 3600: loss 1.7566, time 1898.96ms, mfu 0.18%
iter 3610: loss 1.7522, time 162.16ms, mfu 0.18%
iter 3620: loss 1.7873, time 180.97ms, mfu 0.18%
iter 3630: loss 1.6991, time 163.17ms, mfu 0.18%
iter 3640: loss 1.6118, time 161.46ms, mfu 0.18%
iter 3650: loss 1.4223, time 163.61ms, mfu 0.19%
iter 3660: loss 1.6822, time 162.17ms, mfu 0.19%
iter 3670: loss 1.6539, time 164.36ms, mfu 0.19%
iter 3680: loss 1.6619, time 165.50ms, mfu 0.19%
iter 3690: loss 2.0044, time 158.69ms, mfu 0.19%
step 3700: train loss 1.5574, val loss 1.5598
saving checkpoint to out-python-peps-char
iter 3700: loss 1.6842, time 2099.83ms, mfu 0.18%
iter 3710: loss 1.7363, time 163.41ms, mfu 0.18%
iter 3720: loss 1.7340, time 160.78ms, mfu 0.18%
iter 3730: loss 1.5837, time 166.60ms, mfu 0.18%
iter 3740: loss 1.5616, time 162.80ms, mfu 0.19%
iter 3750: loss 1.7806, time 164.93ms, mfu 0.19%
iter 3760: loss 1.7392, time 166.84ms, mfu 0.19%
iter 3770: loss 1.5292, time 162.36ms, mfu 0.19%
iter 3780: loss 1.7059, time 163.48ms, mfu 0.19%
iter 3790: loss 1.6123, time 162.79ms, mfu 0.19%
step 3800: train loss 1.4965, val loss 1.5963
iter 3800: loss 1.6724, time 1910.53ms, mfu 0.18%
iter 3810: loss 1.6942, time 163.19ms, mfu 0.18%
iter 3820: loss 1.6521, time 163.01ms, mfu 0.18%
iter 3830: loss 1.6288, time 162.13ms, mfu 0.18%
iter 3840: loss 1.9918, time 182.46ms, mfu 0.18%
iter 3850: loss 1.5846, time 163.91ms, mfu 0.19%
iter 3860: loss 1.5575, time 163.38ms, mfu 0.19%
iter 3870: loss 1.6518, time 166.00ms, mfu 0.19%
iter 3880: loss 1.7276, time 163.78ms, mfu 0.19%
iter 3890: loss 1.6459, time 164.85ms, mfu 0.19%
step 3900: train loss 1.4477, val loss 1.5269
saving checkpoint to out-python-peps-char
iter 3900: loss 1.4394, time 2197.16ms, mfu 0.17%
iter 3910: loss 1.6200, time 179.92ms, mfu 0.18%
iter 3920: loss 1.7070, time 167.86ms, mfu 0.18%
iter 3930: loss 1.7698, time 161.85ms, mfu 0.18%
iter 3940: loss 1.5829, time 161.94ms, mfu 0.18%
iter 3950: loss 1.6896, time 163.17ms, mfu 0.19%
iter 3960: loss 1.5704, time 161.78ms, mfu 0.19%
iter 3970: loss 1.4399, time 172.25ms, mfu 0.19%
iter 3980: loss 1.7062, time 168.82ms, mfu 0.19%
iter 3990: loss 1.5533, time 187.08ms, mfu 0.19%
step 4000: train loss 1.5597, val loss 1.5972
iter 4000: loss 1.7324, time 1894.53ms, mfu 0.17%
iter 4010: loss 1.6720, time 188.81ms, mfu 0.17%
iter 4020: loss 1.6675, time 161.73ms, mfu 0.18%
iter 4030: loss 1.6128, time 165.12ms, mfu 0.18%
iter 4040: loss 1.6251, time 161.60ms, mfu 0.18%
iter 4050: loss 1.6048, time 162.37ms, mfu 0.18%
iter 4060: loss 1.5914, time 163.45ms, mfu 0.19%
iter 4070: loss 1.7058, time 163.59ms, mfu 0.19%
iter 4080: loss 1.6742, time 180.85ms, mfu 0.19%
iter 4090: loss 1.6749, time 164.07ms, mfu 0.19%
step 4100: train loss 1.4870, val loss 1.5240
saving checkpoint to out-python-peps-char
iter 4100: loss 1.6794, time 2164.64ms, mfu 0.17%
iter 4110: loss 1.5833, time 165.95ms, mfu 0.17%
iter 4120: loss 1.4470, time 185.83ms, mfu 0.18%
iter 4130: loss 1.6898, time 160.90ms, mfu 0.18%
iter 4140: loss 1.4611, time 165.60ms, mfu 0.18%
iter 4150: loss 1.7284, time 163.37ms, mfu 0.18%
iter 4160: loss 1.4878, time 183.35ms, mfu 0.18%
iter 4170: loss 1.5392, time 160.89ms, mfu 0.19%
iter 4180: loss 1.6032, time 163.09ms, mfu 0.19%
iter 4190: loss 1.6347, time 162.95ms, mfu 0.19%
step 4200: train loss 1.5239, val loss 1.5373
iter 4200: loss 1.6192, time 1885.46ms, mfu 0.17%
iter 4210: loss 1.5643, time 164.74ms, mfu 0.18%
iter 4220: loss 1.5764, time 164.68ms, mfu 0.18%
iter 4230: loss 1.6121, time 185.84ms, mfu 0.18%
iter 4240: loss 1.7452, time 167.00ms, mfu 0.18%
iter 4250: loss 1.7670, time 166.09ms, mfu 0.18%
iter 4260: loss 1.6667, time 163.55ms, mfu 0.18%
iter 4270: loss 1.6600, time 163.45ms, mfu 0.19%
iter 4280: loss 1.4909, time 165.07ms, mfu 0.19%
iter 4290: loss 1.5410, time 169.44ms, mfu 0.19%
step 4300: train loss 1.5069, val loss 1.5214
saving checkpoint to out-python-peps-char
iter 4300: loss 1.6056, time 2306.62ms, mfu 0.17%
iter 4310: loss 1.7149, time 165.90ms, mfu 0.17%
iter 4320: loss 1.6821, time 162.67ms, mfu 0.18%
iter 4330: loss 1.6915, time 161.66ms, mfu 0.18%
iter 4340: loss 1.5789, time 168.08ms, mfu 0.18%
iter 4350: loss 1.7868, time 163.27ms, mfu 0.18%
iter 4360: loss 1.6744, time 161.43ms, mfu 0.19%
iter 4370: loss 1.7203, time 161.55ms, mfu 0.19%
iter 4380: loss 1.6064, time 165.75ms, mfu 0.19%
iter 4390: loss 1.7470, time 162.24ms, mfu 0.19%
step 4400: train loss 1.4723, val loss 1.5509
iter 4400: loss 1.5397, time 1896.89ms, mfu 0.17%
iter 4410: loss 1.5611, time 168.01ms, mfu 0.18%
iter 4420: loss 1.5778, time 165.88ms, mfu 0.18%
iter 4430: loss 1.5911, time 179.10ms, mfu 0.18%
iter 4440: loss 1.7101, time 162.29ms, mfu 0.18%
iter 4450: loss 1.7752, time 161.45ms, mfu 0.19%
iter 4460: loss 1.6612, time 160.77ms, mfu 0.19%
iter 4470: loss 1.6011, time 164.17ms, mfu 0.19%
iter 4480: loss 1.6383, time 161.11ms, mfu 0.19%
iter 4490: loss 1.6578, time 162.92ms, mfu 0.19%
step 4500: train loss 1.4625, val loss 1.4841
saving checkpoint to out-python-peps-char
iter 4500: loss 1.5765, time 2070.37ms, mfu 0.17%
iter 4510: loss 1.5513, time 161.39ms, mfu 0.18%
iter 4520: loss 1.5143, time 160.98ms, mfu 0.18%
iter 4530: loss 1.7307, time 179.88ms, mfu 0.18%
iter 4540: loss 1.6566, time 163.43ms, mfu 0.18%
iter 4550: loss 1.7524, time 162.34ms, mfu 0.19%
iter 4560: loss 1.6054, time 163.84ms, mfu 0.19%
iter 4570: loss 1.6432, time 162.32ms, mfu 0.19%
iter 4580: loss 1.6222, time 173.01ms, mfu 0.19%
iter 4590: loss 1.5922, time 159.84ms, mfu 0.19%
step 4600: train loss 1.4737, val loss 1.4831
saving checkpoint to out-python-peps-char
iter 4600: loss 1.6498, time 2098.05ms, mfu 0.17%
iter 4610: loss 1.5962, time 161.52ms, mfu 0.18%
iter 4620: loss 1.6292, time 162.32ms, mfu 0.18%
iter 4630: loss 1.5728, time 162.26ms, mfu 0.18%
iter 4640: loss 1.6465, time 165.81ms, mfu 0.19%
iter 4650: loss 1.3893, time 161.83ms, mfu 0.19%
iter 4660: loss 1.5676, time 170.61ms, mfu 0.19%
iter 4670: loss 1.6933, time 163.18ms, mfu 0.19%
iter 4680: loss 1.7008, time 164.96ms, mfu 0.19%
iter 4690: loss 1.4823, time 161.03ms, mfu 0.19%
step 4700: train loss 1.4691, val loss 1.4626
saving checkpoint to out-python-peps-char
iter 4700: loss 1.5413, time 2091.03ms, mfu 0.18%
iter 4710: loss 1.6946, time 161.74ms, mfu 0.18%
iter 4720: loss 1.5913, time 167.41ms, mfu 0.18%
iter 4730: loss 1.5271, time 162.47ms, mfu 0.18%
iter 4740: loss 1.5656, time 162.64ms, mfu 0.19%
iter 4750: loss 1.5622, time 162.24ms, mfu 0.19%
iter 4760: loss 1.6752, time 161.58ms, mfu 0.19%
iter 4770: loss 1.5303, time 163.06ms, mfu 0.19%
iter 4780: loss 1.5878, time 162.75ms, mfu 0.19%
iter 4790: loss 1.5533, time 164.12ms, mfu 0.19%
step 4800: train loss 1.4403, val loss 1.5020
iter 4800: loss 1.5425, time 1883.88ms, mfu 0.18%
iter 4810: loss 1.6820, time 163.45ms, mfu 0.18%
iter 4820: loss 1.5900, time 162.54ms, mfu 0.18%
iter 4830: loss 1.6629, time 161.99ms, mfu 0.18%
iter 4840: loss 1.5858, time 162.08ms, mfu 0.19%
iter 4850: loss 1.6204, time 163.16ms, mfu 0.19%
iter 4860: loss 1.4941, time 162.83ms, mfu 0.19%
iter 4870: loss 1.4298, time 165.45ms, mfu 0.19%
iter 4880: loss 1.5327, time 162.88ms, mfu 0.19%
iter 4890: loss 1.6551, time 162.14ms, mfu 0.19%
step 4900: train loss 1.4436, val loss 1.4341
saving checkpoint to out-python-peps-char
iter 4900: loss 1.4756, time 2090.28ms, mfu 0.18%
iter 4910: loss 1.4568, time 163.83ms, mfu 0.18%
iter 4920: loss 1.7181, time 169.17ms, mfu 0.18%
iter 4930: loss 1.5902, time 162.39ms, mfu 0.18%
iter 4940: loss 1.7921, time 164.22ms, mfu 0.19%
iter 4950: loss 1.6566, time 161.02ms, mfu 0.19%
iter 4960: loss 1.4211, time 165.87ms, mfu 0.19%
iter 4970: loss 1.4426, time 162.19ms, mfu 0.19%
iter 4980: loss 1.5027, time 164.04ms, mfu 0.19%
iter 4990: loss 1.5483, time 159.71ms, mfu 0.19%
step 5000: train loss 1.4438, val loss 1.4542
iter 5000: loss 1.4665, time 1889.73ms, mfu 0.18%… and let’s try the output again.
➍ Training a tiny transformer model
! (cd 'tmp/nanoGPT' && \
python3 sample.py \
--out_dir=out-python-peps-char \
--num_samples=1 \
--max_new_tokens=500 \
--device=cpu \
--seed="$(date +%s)" \
--start='A good Python code is ')Overriding: out_dir = out-python-peps-char
Overriding: num_samples = 1
Overriding: max_new_tokens = 500
Overriding: device = cpu
Overriding: seed = 1694416832
Overriding: start = A good Python code is
number of parameters: 10.75M
Loading meta from data/python_peps_char/meta.pkl...
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
A good Python code is not performatication
or to problem and systems. The allowing may are supported to be value of
expected ``except`` and ``updatementer``none``. The is `size to work the
``index.tarse`` auth the path that of the same to referreferent and like
attributed to item, for version 1.4 is a possible in the version the from
statementially returning the part stated by a value of the feel file
the beginal for all namest a respured to proposes of the example with ``__``, it implementation is methods
developer ...
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~Weights & Biases Integration
https://api.wandb.ai/links/karmi/2501lunz
➍ Training a tiny transformer model